May 11, 2021
2175
1. How to give full play to the performance of SSD
First, let's take a look at the use of traditional HDD:
1. The protocol generally uses SAS and SATA interfaces;
2. Linux IO scheduling needs to use elevator algorithm to rearrange IO to optimize the path of the head;
3. Enterprise-level storage usually uses Raid cards for data protection.
In terms of interface protocol, with the invention of SSD, NVMe protocol came into being. Compared with the single-queue mechanism of SAS and SATA, NVMe can have 65,535 queues at most, and directly adopts PCIe interface, which eliminates link and protocol bottlenecks.
In terms of control card ecology, major manufacturers have also launched their own NVMe control card chips, including PMC (now part of Microchip), LSI, Marvel, Intel, Huirong, and domestic Derui. The technology is also very mature.
In the Linux driver and IO protocol stack, corresponding optimizations have also been made. As shown in the figure below, the NVMe driver can directly bypass the traditional scheduling layer specifically designed for HDD, greatly shortening the processing path.
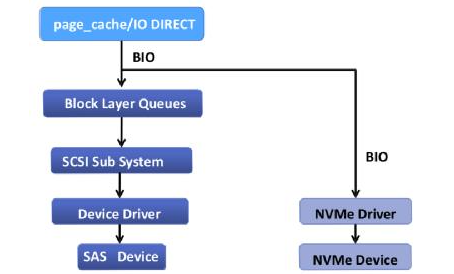
So far, in order to give full play to the performance of SSDs, the first two of the three traditional HDD problems mentioned above have been solved. However, in the enterprise market, NVMe-based Raid has never been a good solution. The Raid5/Raid6 data protection mechanism (N+1, N+2) most widely used by traditional enterprises, usually strips data into pieces, then calculates redundant ParityCode (parity code), and stores the data in With multiple hard disks, writing new data is usually a "read-rewrite" mechanism. This mechanism itself has become a performance bottleneck, and "read and write" has a great loss in the service life of the SSD. In addition, because the NVMe protocol puts the control card inside the NVMe disk, the IO is all completed by the DMA module inside the NVMe disk, which brings greater difficulties to the design of the Raid card based on NVMe. At present, there are few available solutions for this kind of Raid control card in the market, and the performance can not give play to the advantages of NVMe, so it has not been widely used.
Based on the current situation, many enterprise-level storage solutions are still using SAS/SATA SSDs plus traditional Raid cards. In this way, there will be two problems that have been resolved before, and the performance of SSDs cannot be fully utilized.
However, this situation is also changing. The NVMeoverTCP (NVMe/TCP) storage cluster solution invented by LightbitsLabs has dealt with this problem well. The solution uses a self-developed data accelerator card and adopts the ErasureCode (erasure code) mechanism to achieve a random write performance of more than 1MIOPS, and can avoid the service life loss caused by "read and write". In addition, Lightbits proposed the ElasTIcRaid mechanism, which provides flexible N+1 protection (similar to Raid5). Compared with the traditional Raid5, which requires hot spare disks or needs to replace damaged disks in time, this mechanism can automatically occur after a hard disk is damaged. The balance forms a new protection. For example, there are 10 disks in a node, and 9+1 protection is adopted. When a disk is damaged, the system will automatically switch to the 8+1 protection state, and the original data will be rebalanced to the new protection state. Significant improvements have been achieved in terms of maintainability and data security. In addition, the data acceleration card can achieve 100Gb line-speed compression, which significantly increases the available capacity, thereby greatly reducing the cost of system usage.
2. How to improve the durability of NVMe disks
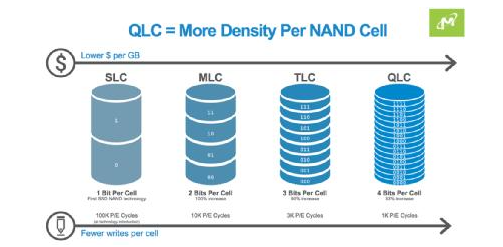
At present, the most widely used SSD is based on NAND particles, and an inherent problem of NAND is endurance. And with the development of technology, the density of NAND is getting higher and higher. The latest generation has reached QLC (4bitsperCell), and the number of times that each cell can be erased and written is also decreasing (1KP/ECycles). The development trend is shown in the figure below.
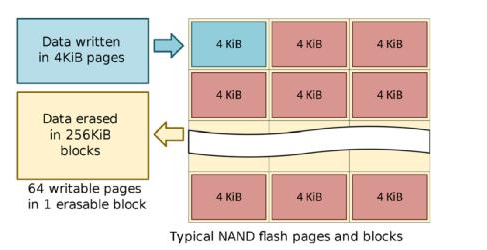
In addition, there is a feature of the use of NAND, that is, the smallest erasable unit is relatively large. As shown in the figure below, when writing, you can write to it in units of 4KB, but when erasing (such as modifying the original data), you can only write to it. 256KB is operated as a particle (different SSDs have different sizes, but the principle is the same). This is easy to form a hole and trigger the GC (GarbagecollecTIon) data movement of the SSD, which in turn leads to the so-called write amplification phenomenon, which will further affect the durability of the disk.
In enterprise-level storage, the "read and write" mechanism of Raid5/6 is usually used, which will further amplify the number of disk write operations. In general use scenarios, it is about twice the loss of direct write mode. In addition, many Raid5 will also activate the Journal mechanism, which will further deplete the life of the disk.
Finally, for the latest QLC, another factor needs to be considered in use-IndirecTIonUnit (IU). For example, some QLC disks use 16KB IU, if you want to write a smaller IO, it will also trigger the internal "read and rewrite", which will damage the service life again.
It can be seen from this that NAND-based SSDs are still relatively delicate. However, as long as it can be used correctly, these problems can still be avoided. For example, taking a commonly used QLC disk as an example, through the following two sets of parameters related to performance and durability, it can be seen that sequential writing is 5 times that of random writing in terms of durability, and performance is 26 times:
l Write 0.9DWPD sequentially, and write 0.18DWPD at random 4K;
l Write 1600MB/s sequentially, and write 15KIOPS (60MB/s) at random 4K.
Through the above analysis, it is found that it is very important to be able to use the disk in an optimal working condition. The good news is that some advanced solutions, such as Lightbits' full NVMe cluster storage solution, can solve this problem. This scheme avoids the disadvantages of Raid "read and rewrite" by turning random IO into sequential IO, and the unique ElasTIcRaid technology, thereby greatly improving the durability and random performance of the disk.
3. how to reduce the cost of use
As SSD is a new technology relative to HDD, coupled with the contradiction between the industry's production scale and demand, the current price is still higher than HDD. So how to reduce the cost of using SSD has become very important.
The most important part of reducing usage costs is to make full use of SSDs, both in terms of capacity and performance. But for now, most NVMe disks are used directly on the application server, and this method is very easy to cause a lot of capacity and performance waste, because only the application on this server can use it. According to research findings, using this DAS (DirectAttached Storage) method, the utilization rate of SSD is about 15%-25%.
A better solution to this problem is the "decoupling" architecture that has been widely accepted in the market in recent years. After decoupling, turn all the NVMe disks into a large storage resource pool, and take as much as the application server uses. As long as the total number is sufficient, the utilization rate can be pushed to 80% very easily. In addition, because resources are concentrated, there can be more means and methods to reduce costs, such as compression. For example, an average application data compression ratio of 2:1 is equivalent to doubling the available capacity, and it is equivalent to halving the price per GB. Of course, compression itself will also bring some problems, such as compression itself is more CPU-intensive, and many storage solutions will greatly reduce the performance after compression is turned on.
Aiming at the problem of compression, Lightbits' NVMe/TCP cluster storage solution can be solved by a storage accelerator card. The card can achieve 100Gb line-speed compression, and does not consume CPU, and does not increase delay. With such a solution, there is almost no additional cost for the compression function. In addition, as mentioned earlier in the introduction to improving durability, the Lightbits solution can increase the service life and support the use of QLC disks. From the perspective of the entire life cycle, the use cost will also be greatly reduced. In general, through decoupling to improve usage efficiency, compression to increase available capacity, optimization to increase service life, or to enable QLC, after such numerous improvements, the cost of using SSD can be greatly controlled.
The above has analyzed how to use SSD disks from the three aspects of performance, durability, and use cost. It can be seen that it is not easy to use NVMeSSD disks well. Therefore, for the average user, choosing a good storage solution is very important. To this end, the Israeli innovation company Lightbits, with the mission of giving full play to the maximum value of NVMe disks, invented the NVMe/TCP protocol, and launched a new generation of all-NVMe cluster storage solutions, which can help users easily use SSD disks.







