November 09, 2020
2273
In the SSIS architecture, Package is the most important part of SSIS. In essence, Package is a unit that performs tasks in an orderly manner. The core of the package is the control flow, which is used to coordinate the execution sequence of all components in the package. The data flow is the core component of the control flow. It is used to extract data into the server memory, transform the data and write the data into the target structure.
1. Control flow
Control flow is used to coordinate the execution order of all components in the package. These components are composed of Tasks and containers and are controlled by priority constraints.
The control flow consists of three major components, namely Task, Container and Priority Constraint.
Containers are used to group Tasks together. In addition to visual grouping, containers also allow users to define variables and event handlers whose scope is within the scope of the container.
Task is an independent unit of work that provides an interface for the package to implement specific functions.
Priority constraints not only connect Tasks together, but also specify the order of Task execution.
Tasks are executed in the order specified by the PrecedenceConstraint. Before a Task can work, the Package must complete its previous Task, regardless of whether the result of the previous Task execution is success, failure or completion.
1. Priority constraints
Priority constraints are connectors that connect Tasks together and define the execution order of Tasks. The priority constraint defines the execution path and conditions of the Task. Only when the conditions of the priority constraint are met, can the next task be executed according to the connection path. For example, in the control flow shown in the figure below, the priority constraint connects ExecuteSQLTask and DataFlowTask together, and stipulates that DataFlowTask will be executed only after ExecuteSQLTask has been executed.
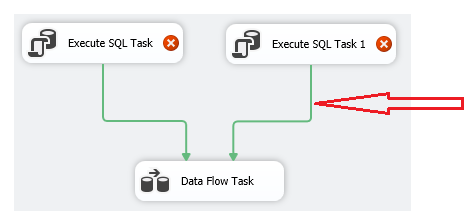
To create a priority constraint for two tasks, the constraint value or expression must be set. When the constraint value or expression is True, the constraint condition is satisfied.
There are four precedence constraint evaluation operations (EvaluaTIonoperaTIon):
Constraint (Constraint), according to the result of the constraint to determine the state of the constraint
Expression (Expression), according to the result of the expression to determine the state of the constraint
Expression and Constraint (ExpressionandConstraint), according to the combination of expression and constraint results to determine the state of the constraint
Expression or Constraint (ExpressionorConstraint), according to one of the results of the expression or constraint to determine the state of the constraint
According to different constraint options, there are two types of constraint values: Value and expression:
When the evaluation option is a constraint, the constraint values are: Success, Failure and CompleTIon;
When the evaluation option is an expression, the user needs to write the expression;
There are three valid values for constraint values, their meanings are:
Success constraint: It means that the current task will be executed only when the predecessor or container succeeds;
Failure constraint: It means that the current task will be executed only when the predecessor task or container fails;
Completion constraint: indicates that the current task will be specified only when the predecessor task or container is completed (regardless of failure or success)
When multiple constraints are created on a task, a logical combination of multiple constraints must be set. When set to logical AND, multiple priority constraints are True at the same time to meet the conditions of priority constraints; when set to logical OR, as long as one constraint is True, the conditions of priority constraints are met. Multiple constraints enable the current Task to be executed when the predecessors are successful (logical AND), or any predecessor tasks are successful (logical OR).
2. Priority constraints control Task concurrency
Control flow cannot transfer data between Task components. It acts as a Task scheduler for serial or parallel execution of tasks. If no priority constraint is set between the two tasks, then the two tasks are executed concurrently. When designing the Package, you should maximize the concurrent processing capabilities of the Task component, so that you can make full use of the server's system resources and help reduce the time for ETL execution.
3. The Task component maintains synchronization through priority constraints
Priority constraints are set between Task components. The downstream task will only be executed after the upstream task is completed; the downstream task will not be executed until the upstream task is completed. Therefore, Task is synchronized.
Task synchronization is manifested in two aspects:
Between Tasks: A Task must be completed (successful, failed, or completed) before the operation is transferred. For a Task to run, all upstream tasks must be completed, otherwise it will not be executed. The execution order of tasks is defined by priority constraints.
Single Task: The execution thread of the SSIS will not be released before the task is executed, that is, the execution of the SSISTask is exclusive to the thread resources of the server until the task is completed, otherwise the thread resources will not be released.
2. Data flow
The data flow (DataFlow) is the core component of the control flow. It is used to extract data into the server memory, transform the data and write the data into the target structure. Since the data flow task loads data into the server memory for conversion, SSIS is an ETL tool in memory, which allows SSIS to efficiently perform data conversion operations. The core function of the data stream is to extract the data into the memory of the server, after converting the data, to write the data to another destination. Data is moved from the source to the destination, using a memory pipeline (Pipeline). When the data is in the pipeline, you can use transformation components to clean and process the data.
Data flow has the characteristics of flow, data extraction, conversion and loading are carried out at the same time. The SSIS engine processes data concurrently in the form of streams, which means that the data is not loaded all at once, but divided into multiple parts that are not repeated to form a stream, which continuously flows from upstream components to downstream components. In the process of data flow, all transformation components of the data flow process the data flow at the same time. After the upstream component has processed a batch of data, it is handed over to the downstream component to continue processing, while the upstream component continues to process the next batch of data. Data flows between components, and each component processes different parts of the data at the same time until all data processing is completed.
The data flow has the function of feedback and automatic adjustment. If the processing speed of the downstream component is under pressure, then SSIS will apply reverse pressure to the upstream component, and the SSIS engine will start the automatic adjustment mechanism to make the data flow speed of the upstream component. Slow down, so as to achieve dynamic balance.
The data flow task consists of four parts: source, conversion, destination and path. They are used to load data into the memory, convert the data in the memory, and transfer the data in the memory to the target. The data is "moved" according to the path. ":
Source: Used to specify the location of the external data source, load the external data into the memory, and output data to downstream components.
Conversion: Conversion is done in memory. It is used to change the data in the pipeline and affect the data in the memory data pipeline. It is the core function of the data flow.
Purpose: At the end of the data pipeline, the data leaves the data pipeline and outputs the data to external storage.
Path: The connection between data flow components is called a path, and data is transferred according to the path, which can be regarded as the route the data takes.
The external data source is the source of the data pipeline, usually expressed as a connection (ConnecTIon). SSIS accesses the external data source through the connection. The connection manager is used to set the connection properties, mainly used to centrally set the connection string for accessing the data source. , The connection manager can be shared by multiple components, or shared by multiple packages.
1. Buffer for data stream
The data pipeline is the pipeline for data circulation. The data flow uses memory to temporarily store the data in the data flow. This means that when the data is extracted from an external source to the SSIS engine, the data will be stored in a pre-allocated memory buffer. According to the width of the data row (the number of bytes in all columns in a row), set the DefaultBufferMaxRows property to adjust the maximum number of data rows that the buffer can hold, or directly set the DefaultBufferSize property to adjust the size of the buffer.
The buffer of the data stream can be understood as a two-dimensional table, each row has a fixed length, and the position of each column is fixed. The SSIS engine allocates a set of buffers in advance according to the resources and pressure of the server, and each buffer stores a unique subset of the complete data set. When converting the data stream, the SSIS engine backend uses a more effective way: to the same buffer, apply the conversion components one by one, which is better than copying the converted data to another buffer and then applying the next one Conversion components are more efficient. However, in some cases, the SSIS engine needs to copy the buffer or even intercept the data stream, and then transform the entire data set, for example, aggregation and sorting.
The ideal situation for the SSIS engine to process data is: all conversions are applied to the same buffer, and the conversion is performed on-site to process the data. However, the reality is not always ideal. Some conversion components need to copy buffers in order to pass data downstream.
When the data flow passes through the conversion component, whether the SSIS engine needs to copy the buffer is related to the blocking characteristics of the conversion and the communication mechanism.
2. The blocking characteristics of the conversion: non-blocking (flow), semi-blocking and blocking
Non-blocking: immediately transfer data from the pipeline to the downstream conversion
Semi-blocking: the conversion of increasing the data to a certain amount before passing it downstream
Blocking: After receiving all the data, it is passed to the downstream conversion
Most conversions are streaming, which means that when a conversion is applied to a row, it does not prevent the data from moving to the next conversion. Sorting transformations and aggregation transformations are blocking, which means that each transformation needs to use a complete data set before passing data to a transformation, and will not release any data to downstream components before the end of the transformation. By using a blocking conversion component in the data flow town Nanguan, the data flow will be intercepted, and all rows will stay in the blocking conversion component until the last line flows into the conversion component.
Blocking conversion is very inefficient and resource intensive. Because all data is intercepted, the server must use a lot of memory to store the data, or if the server does not have enough memory, the server will temporarily store part of the data on the disk. This leads to IO overhead; because operations such as sorting and aggregating a large amount of data require a large amount of CPU resources and memory resources.
3. The communication mechanism of the conversion component
The communication of the conversion component means that the conversion component passes the data to the next conversion component. If the buffer used by the input is different from the buffer used by the output, then the converted output is asynchronous, in other words, the asynchronous conversion component does not Able to perform the specified operation and maintain the buffer area (the number of rows or the order of the rows), so the data must be copied to achieve the desired results. The asynchronous conversion component receives the output buffer of the upstream component, and then creates a new buffer to output to the next component.
If the buffer used by the input and the buffer used by the output are the same, the converted output is synchronous, and the synchronous conversion component will not create a new buffer, but reuse the buffer.
The life cycle of the buffer starts from the creation of the buffer to the end of the asynchronous conversion component. Because asynchronous conversion components need to create additional buffers, consume Server's memory resources, and reduce the performance of Server processing data, the ideal PackageDesign is a DataFlow that uses only one buffer to complete all conversion processing operations, and all conversions are synchronous output of. In actual work, we can try not to apply asynchronous conversion components, or reduce the number of buffer creation, and extend the life cycle of the buffer as much as possible.
4. Identify the converted synchronous output and asynchronous output
The buffer of the data stream can be regarded as a two-dimensional table. Each row has a fixed length and the position of each column is fixed. Therefore, the identifiers of a column in the same buffer are the same. If the column is copied to the new buffer, then the identifier of the column changes. SSISEngine uses the LineageID attribute to identify each column in the buffer.
In the advanced editor of the conversion component, each column has a LineageID attribute, which is a pointer to the buffer and identifies the position of the column in the buffer.
If the conversion output is synchronous, then the LineageID attribute of the same column is the same in the converted output and input. If the conversion output is asynchronous, then the LineageID attribute of the same column is different in the converted output and input.
For example, the initial LineageID value of Column1 is 193. If the conversion output is synchronized, in the converted Input and Output, you can see that the LineageID of Column1 is 193.
5. Application and release of data stream buffer
The data source component creates a new buffer and assigns the LineageID value to the corresponding data column.
When the buffer data is loaded into the data destination component, the data destination component will release the buffer.
The asynchronous conversion component will terminate the input buffer and create a new output buffer.
The synchronous conversion component reuses the input buffer and serves as the output buffer to be passed to the next conversion component.
3. Asynchronous conversion example
Asynchronous conversion output means: the input buffer of the conversion is different from the output buffer. For data flow tasks that only include OLEDBSource and Sort conversion, in the Sort conversion, the output column has the LineageID attribute, when the data column is stored in the data for the first time In the stream, the SSIS engine determines the LineageID of the column, which is used to identify the location of the buffer area of the data stream.
1. Data source components
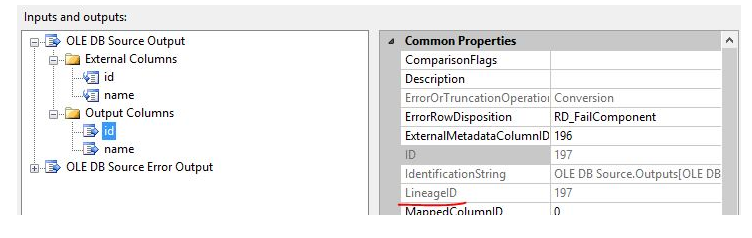
The data source component contains external columns and output columns. The external columns are directly derived from the external data source, and the output columns are the data that the data source outputs downstream. The data source component creates a buffer, loads external data into the buffer, and assigns LineageID to the buffer area. This buffer is the output of the data source component.
2. Sort component
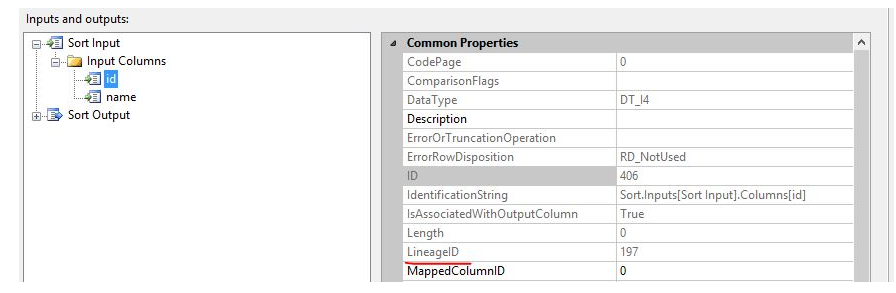
The Sort component receives the output data of the data source component. For the input of the Sort component (SortInput), the LineageID of the ID column is 197, which is the same as the LineageID attribute of the output ID column of the data source. This means that the Sort conversion directly uses the data source The output is used as the input of the Sort transformation.

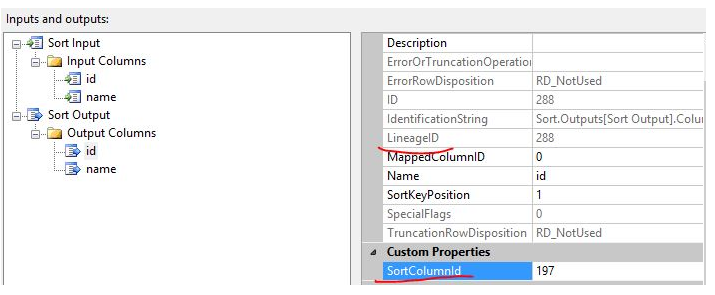
Sort output (SortOutput), the LineageID attribute value of the ID column is 288. The reason why there are different LineageID values is because the output of the Sort conversion is asynchronous, and the input buffer and the output buffer are different. Therefore, the output of the Sort conversion A new column identifier is required.
The SortColumnID attribute is used to specify the LineageID of the input column related to the output column. The SortColumnID attribute value of the output column ID is 197, which is the LineageID of the input column.
All semi-blocking and blocking conversions are output asynchronously. These conversions do not directly pass the input buffer downstream because the data needs to be intercepted for processing and reorganization.
4. Synchronous conversion example
Conditional split conversion (ConditionalSplit) is a non-blocking component. In data flow tasks, conditional split components are used to separate the output of data source components to different purposes according to specific conditions.
1, ConditionalSplit component
Open the ConditionalSplit editor, select Case1, and view the attributes SynchronousInPutID and IdentificationString:
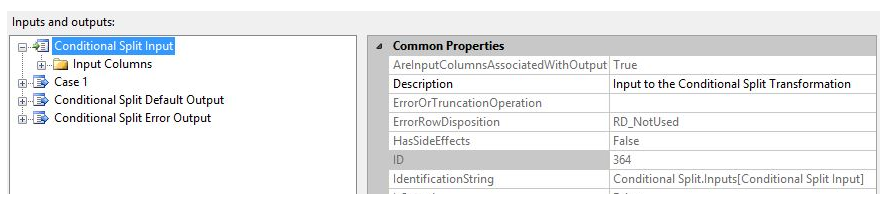
IdentificationString: used to specify the data stream of the component, and its value has a string with a specific format, for example: ConditionalSplit.Inputs[conditionalSplitinput],
SynchronousInPutID: Used to specify the input ID of the row related to the output of the component, and its value is the input IdentificationString.
If the component’s attribute SynchronousInPutID is None, it means that the component will create a new output stream and the conversion output is asynchronous. If the component’s attribute SynchronousInPutID is an IdentificationString, it means that the component’s output and input use the same buffer.
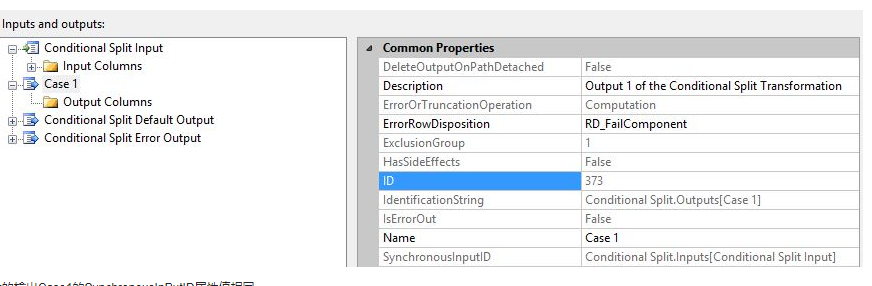
Select the input of ConditionalSplit and view the value of the attribute IdentificationString, which is the same as the SynchronousInPutID attribute value of the component's output Case1.
2. Verify the LineageID value
Look at the InputColumns of the Sort component, the LineageID of the ID column is 197, which is the same as the output of the data source component and the input of ConditionalSplit, indicating that ConditionalSplit does not create a new data buffer, but directly uses the buffer created by the data source for conversion.
Conclusion: In the synchronous conversion output, when the conversion logic is completed, the buffer will be passed to the downstream conversion immediately, that is, the conversion input and the conversion output use the same buffer to avoid copying the buffer to the output, so the LineageID of the same column Are the same.
The user can identify the synchronous conversion component and the asynchronous conversion component through the advanced editor, and view the output SynchronousInPutID property. If the SynchronousInPutID property value is None, then the component output is asynchronous. If the value is not None, it is a string in the IdentificationString format. Then the conversion is synchronous.







