October 28, 2020
3493
With the development of information technology in modern society and the intelligence of human life, the amount of global data is expanding and increasing without limit. Although traditional storage has the advantages of mature technology, good performance, and high availability, its shortcomings are becoming more and more obvious in the face of massive data: such as poor scalability and high cost.
In order to overcome the above shortcomings and meet the storage needs of massive data, distributed storage technologies have appeared on the market. The rise of distributed storage is inseparable from the development of the Internet. Internet companies usually use large-scale distributed storage systems due to their big data and asset-light characteristics.
This article will chat with readers and friends about some mainstream distributed storage storage frameworks currently on the market.
Distributed storage technology
1. What is distributed storage
Before understanding what distributed storage is, let's first understand the general history of storage over the past few decades.
Direct Attached Storage (DAS): Storage and data are directly connected, with poor scalability and flexibility.
Centralized storage (SAN, NAS): There are various types of equipment, which are interconnected through IP/FC networks and have a certain degree of scalability. However, they are limited by the controller's ability and have limited expansion capabilities. At the same time, equipment needs to be replaced in its life cycle, and data migration requires a lot of time and effort.
Distributed storage: Based on standard hardware and distributed architecture, it realizes 1000-node/EB-level expansion, and can uniformly manage multiple types of storage such as blocks, objects, and files.
Distributed storage is to store data dispersedly on multiple storage servers, and these scattered storage resources form a virtual storage device. In fact, the data is stored dispersedly in every corner of the enterprise.
To make a simple analogy, compare data to goods and storage to trucks. Direct storage is equivalent to using ordinary trucks to pull goods; in order to improve the efficiency of pulling goods, use large trucks to pull goods, which is equivalent to centralization. Storage; now, due to too much cargo, large trucks are no longer enough to pull all the cargo. Instead, trains connected section by section are used to pull goods. This is distributed storage. The emergence of distributed systems is to use ordinary machines to complete calculation and storage tasks that a single computer cannot complete. The purpose is to use more machines to process more data.
2. Advantages of distributed storage
Scalable: The distributed storage system can be expanded to hundreds or even thousands of clusters, and the overall performance of the system can grow linearly.
Low cost: Automatic fault tolerance and automatic load balancing of distributed storage systems allow the construction of distributed storage systems on low-cost servers. In addition, linear scalability can also increase and reduce the cost of servers, and realize automatic operation and maintenance of distributed storage systems.
High performance: Whether for a single server or for a distributed storage cluster, distributed storage systems require high performance.
Distributed storage framework
The realization of distributed storage technology is often inseparable from the underlying distributed storage framework. According to its storage type, it can be divided into block storage, object storage and file storage. Among the mainstream distributed storage technologies, HDFS belongs to file storage, Swift belongs to object storage, and Ceph can support block storage, object storage and file storage, so it is called unified storage.
1.HDFS
HDFS is one of the core components of Hadoop and the basis of data storage management in distributed computing. It is designed as a distributed file system suitable for running on general-purpose hardware.
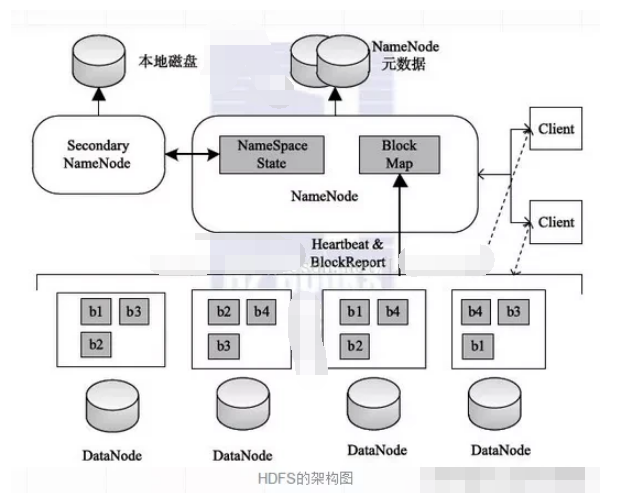
1.1HDFS functional modules
Client
Client is a means for users to interact with HDFS. When a file is uploaded to HDFS, Client divides the file into blocks and then uploads it; Client interacts with NameNode to obtain file location information; interacts with DataNode, reads or Write data; Client can also provide some commands such as NameNode formatting to manage HDFS; at the same time, Client can access HDFS by adding, deleting, modifying and checking HDFS.
NameNode
NameNode is the master architecture of HDFS. It maintains the file system tree and all files and directories in the entire tree. The HDFS file system handles client read and write requests, manages data block mapping information, and configures copy policies. The work is done by the NameNode.
DataNode
The NameNode issues the command, and the DataNode performs the actual operation. DataNode represents the actual stored data block, and can perform read and write operations on the data block.
SecondaryNameNode
The function of the SecondaryNameNode is mainly to assist the NameNode and share its workload; it can assist in the recovery of the NameNode in an emergency, but it cannot replace the NameNode and provide services.

1.2 Advantages of HDFS
1. Fault tolerance: multiple copies of data are automatically saved. By increasing the form of copy, improve fault tolerance. After one of the copies is lost, it can be automatically restored.
2. It can handle big data: it can handle data with a scale of GB, TB, or even PB; it can handle files larger than one million.
3. It can be built on a cheap machine, and the reliability can be improved through the multi-copy mechanism.
1.3 Disadvantages of HDFS
1. Not suitable for low-latency data access: For example, millisecond-level storage data is impossible.
2. Unable to store a large number of small files efficiently: If a large number of small files are stored, it will occupy a large amount of memory of the NameNode to store file directory and block information. This is not desirable, because the memory of the NameNode is always limited. At the same time, the addressing time of small file storage will exceed the read time, which violates the design goal of HDFS.
3. Does not support concurrent writing and random file modification: a file can only be written by one, and multiple threads are not allowed to write at the same time. Only data append is supported, and random modification of files is not supported.
2. Swift
Swift started in 2008. It was originally a distributed object storage service developed by Rackspace, and it was contributed to the OpenStack open source community in 2010. Now it has been deployed to a large-scale public cloud production environment.
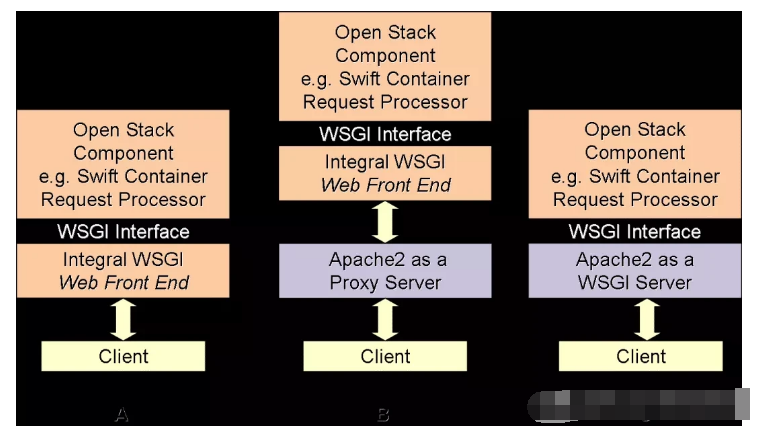
2.1 Swift functional modules
Swift adopts a completely symmetrical, resource-oriented distributed system architecture design, and all components can be expanded to avoid affecting the availability of the entire system due to a single point of failure.
ProxyServer (Proxy Service): Provides object service API externally. ProxyServer first finds the physical location of the operated entity through Ring, and then forwards the request to the corresponding account, container or object service.
AuthenTIcaTIonServer (Authentication Service): Verify the user's identity information and obtain an access token (Token).
CacheServer (cache service): Cache token, account and container information, but will not cache the data of the object itself.
AccountServer (account service): AccountServer is a service process in the storage node responsible for processing the get, head, put, delete, and relicaTIon requests of the Account. A service that provides account metadata and statistical information, and maintains a list of contained containers.
ContainerServer (container service): ContainerServer is the service process in the storage node responsible for processing the get, head, put, delete, and relicaTIon requests of the Container. A service that provides container metadata and statistical information, and maintains a list of contained objects.
ObjectServer (Object Service): ObjectServer is a simple BLOB storage server that can store, retrieve, and delete objects stored in local devices. Provide object metadata and content services, and each object will be stored in the file system as a file.
Replicator (replication service): Detect whether the local copy is consistent with the remote copy, and use Push to update the remote copy.
Updater (update service): Update of object content.
Auditor: Check the integrity of objects, containers, and accounts. If errors are found, the files will be quarantined.
AccountReaper (Account Cleanup Service): Remove the account marked for deletion and delete all the containers and objects it contains.
2.2 Swift technical characteristics
1. Swift's data model adopts a hierarchical structure with three layers: Account/Container/Object (ie account/container/object). There is no limit to the number of nodes in each layer and can be expanded arbitrarily.
2. Swift is based on consistent hashing technology. Through calculation, objects are evenly distributed on virtual nodes in virtual space. When adding or deleting nodes, the amount of data that needs to be moved can be greatly reduced; through the unique data structure Ring (ring), Then map the virtual node to the actual physical storage device to complete the addressing process.
3. Swift defines the rings for accounts, containers and objects respectively. The ring is designed to map virtual nodes (partitions) to a set of physical storage devices and provide a certain degree of redundancy. The data information of the ring includes the storage device list and device information, the mapping relationship between partitions and devices, and the calculation partition Number of displacement.
2.3 Advantages of Swift
1. Extremely high data durability
2. Completely symmetrical system architecture
3. Unlimited scalability
4. No single point of failure
5. It is one of the sub-projects of OpenStack, suitable for deployment in cloud environment
2.4 Disadvantages of Swift
Native object storage does not support real-time file reading, writing and editing functions
3.Ceph
Ceph originated from the work of Sage during his Ph.D. The results were published in 2004, and then contributed to the open source community. After more than ten years of development, it has become the most widely used open source distributed storage platform.
3.1 The main architecture of Ceph
Basic storage system RADOS
The bottom layer of Ceph is RADOS (Distributed Object Storage System), which has the characteristics of reliability, intelligence, and distribution, achieving high reliability, high scalability, high performance, high automation and other functions, and ultimately storing user data. The RADOS system is mainly composed of CephOSD and CephMonitors. The function of CephOSD is to store data, process data replication, recovery, backfill, and rebalance, and provide some monitoring information to CephMonitors by checking the heartbeat of other OSD daemons. CephMonitor maintains various charts showing the status of the cluster, including monitor charts, OSD charts, placement group (PG) charts, and CRUSH charts.
Basic library LIBRADOS
The function of the LIBRADOS layer is to abstract and encapsulate RADOS, and provide APIs to the upper layer to directly develop applications based on RADOS. RADOS is an object storage system, therefore, the API implemented by LIBRADOS is aimed at the object storage function. Physically, LIBRADOS and the applications developed on it are located on the same machine, so it is also called local API. The application calls the LIBRADOSAPI on the machine, and the latter communicates with the nodes in the RADOS cluster through sockets and completes various operations.
Upper application interface
The Ceph upper application interface covers RADOSGW (RADOSGateway), RBD (ReliableBlockDevice) and CephFS (CephFileSystem). Among them, RADOSGW and RBD are based on the LIBRADOS library to provide a higher level of abstraction and more convenient for applications or clients.
Application layer
The application layer is a variety of application methods for each application interface of Ceph in different scenarios, such as object storage applications directly developed based on LIBRADOS, object storage applications developed based on RADOSGW, and cloud host hard drives based on RBD.
3.2 Ceph functional modules
Client: Responsible for storage protocol access and node load balancing.
MON monitoring service: responsible for monitoring the entire cluster, maintaining the health status of the cluster, and maintaining various charts showing the status of the cluster, such as OSDMap, MonitorMap, PGMap and CRUSHMap.
MDS Metadata Service: Responsible for saving the metadata of the file system and managing the directory structure.
OSD storage service: The main function is to store data, copy data, balance data, restore data, and perform heartbeat checking with other OSDs. Generally, one hard disk corresponds to one OSD.
3.3 Advantages of Ceph
1. CRUSH algorithm
The CRUSH algorithm is one of ceph's two major innovations. Simply put, ceph abandons the traditional centralized storage metadata addressing scheme, and instead uses the CRUSH algorithm to complete data addressing operations. The CRUSH algorithm is adopted, with balanced data distribution, high parallelism, and no need to maintain a fixed metadata structure.
2. High availability
The number of data copies in Ceph can be defined by the administrator, and the physical storage location of the copies can be specified through the CRUSH algorithm to separate fault domains, support strong data consistency, suitable for read-more-write-less scenarios; ceph can endure multiple failure scenarios and Automatically try parallel repairs.
3. High scalability
Ceph itself does not have a master node, it is easier to expand, and theoretically, its performance will increase linearly with the increase in the number of disks.
4. Rich features
Ceph supports object storage, block storage and file storage services, so it is called unified storage
3.4 Disadvantages of Ceph
1. Decentralized distributed solutions need to be planned and designed in advance, and require relatively high technical teams.
2. When Ceph expands, due to its balanced data distribution characteristics, the performance of the entire storage system will decrease.
BMJ distributed storage
BMJ is a high-speed, secure, and scalable blockchain infrastructure project. For 5G, in-depth development and optimization of the underlying technology of IPFS, P2P transmission of nodes through slicing technology, realizing the second transmission of hundreds of megabytes of files. From a brand-new perspective, BMJ proposes a new solution based on the design idea of a blockchain-based distributed cloud storage system. In the aspect of data transmission, the data exchange mechanism and the second transmission mechanism are introduced to increase the data transmission speed; in the aspect of data storage, it adopts a An efficient data storage architecture to improve data storage efficiency.
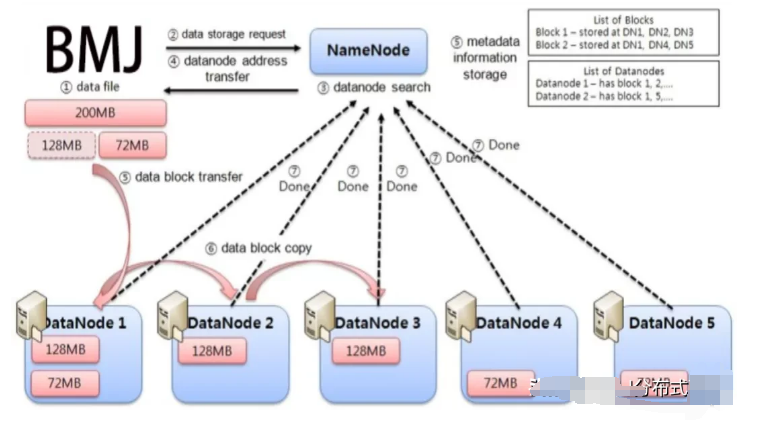
As the leader of distributed storage, BMJ is currently deploying rapidly. In the future, it will form an industrial cluster including cloud storage, cloud computing, and big data, which can better lead the upgrading and transformation of traditional enterprises and promote the development of the entire new economy.
Coming for storage and born for service, BMJ is quietly changing the whole world, changing our lives.







